Blogs
Orchestration on the Cloud
For any data transformation pipeline, it is not a one step process. The conversion of data requires, comparison, datatype conversion, data extraction, comparison, selection and flattening of records, and these steps could be re-run against hundreds of tables in loop.
For eg, to establish a contact data base, we may need to extract names and pincodes, camel case the names, extract address from the pincodes, join the data, attach region timezones to the contact details based on location and populate a final table.
It is not an easy process to define the step by step execution of this pipeline definition. As the source could be across different dataset or storage softwares, and we may need to scale these across millions of rows. This form of orchestration was typically associated with dataflow or airflow in google cloud. Whilst very powerful in its suit of features, both of these have a significant learning curve, unless utilizing one of the tailor made templates for implementation.
Cloud Workflow provides a more simplistic solution, to orchestration of pipelines in the cloud, using yaml like steps. It is not a drag and drop IDE based orchestration tool, so the coding factor still remains, but its concentrated on limited but useful set of step commands. It is a serverless and lightweight implementation of an orchestration tool.
Workflow allows API calls to Google API, which makes it suitable placed to orchestrate multiple services. It is strictly meant to orchestrate and not work as an ETL replacement, hence limiting available functionality. But it can do a bunch of jobs reducing overhead costs on running servers or dataproc clusters.
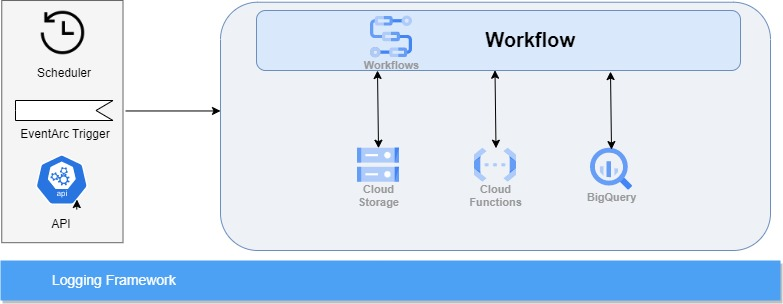
Workflow is controlled through IAM, hence service accounts driving workflow executions are need to be provided granular access to whichever API\apps are being used in the GCP environment. This ensure adequate safety and security concerns.
A typical Cloud workflow is a stepped execution that can be run on schedule, triggered manually or with an evenarc link, which allows it to be executed even on basic log alerts to typical cloud storage file creations. The workflow script is represented by a flowchart which shows the execution parameters and data movement.
Following is an implementation example covering a few of the basic operations supported by Cloud workflow. In this implementation we will –
- Read a list of CSV files from cloud storage
- Store it into a Bigquery table
- Read will be in loop
- Join the Bigquery table with another table for an output extract
- Store the transformed data in a separate table
- logString1:
call: sys.log
args:
text: INFO==>Starting CloudStorage Insert!
severity: INFO
- StoragetoBigQueryLoad:
for:
value: fileName
in: ${FileList}
steps:
- CloudStoragePathForm:
assign:
- filePath: ${"gs://"+bucketName+"/fileName" + timeStamp+".csv"}
- GStoBigQueryLoad:
call: http.post
args:
url: ${urlString}
body:
configuration: {
jobType: LOAD,
load: {
"sourceUris": [
"${filePath}"
],
"destinationTable": {
"projectId": "${project_id}",
"datasetId": "${dataset_id}",
"tableId": "${target_table}"
},
"create_disposition": "${createDisposition}",
"write_disposition": "${writeDisposition}",
"nullMarker": "NA",
"fieldDelimiter": "|",
"sourceFormat": "CSV",
"autodetect": true
},
}
headers:
Content-Type: "application/json"
auth:
type: OAuth2
result: jobLoadRes
- sleep:
call: sys.sleep
args:
seconds: 8
- logEndPoint:
call: sys.log
args:
text: INFO==>Completed CSV read and load to BQ!
severity: INFO
- callBQQuery:
call: googleapis.bigquery.v2.jobs.query
args:
projectId: ${project_id}
body:
useLegacySql: false
query: ${"CALL `projectid.TestData.P_CustomerBaseName2`();"}
result: queryRes
- finalLog:
call: sys.log
args:
text: Workflow Completed. Procedure Run!
severity: INFO